Ricerca full-text per un sito statico
Mantenere un sito web statico (come questo, che è generato “offline” con Jekyll e poi caricato online), è piuttosto semplice e non richiede particolari competenze tecniche. Ma anche le funzionalità che puoi includere per i visitatori sono limitate. Il motivo è semplice: il server che offre al browser le pagine di un sito statico le offre così come sono, senza modificarle prima dell’invio. Faccio un esempio: se volessi pubblicare una pagina dove i visitatori possano vedere il meteo aggiornato di Borgo a Buggiano, dovrei ogni qualche ora mettermi a fare le previsioni, o copiarle da un altro sito, risistemarle e ripubblicare la pagina. Questo perché i “contenuti” sono statici: non cambiano se non li cambiamo a mano.
Ma se il cotenuto che io voglio mostrare NON fosse sulla pagina ma “altrove”, o calcolato non dal server ma dal browser? Potrei anche accontentarmi di non avere io stesso il contenuto da inserire sul sito a mano, ma di prenderlo in prestito o generarlo solo quando la pagina viene aperta da qualcuno sul suo browser. Lascerei, quindi, il lavoro di aggiornamento non al server, ma al browser, al client. Inserendo un po’ di JavaScript sulla pagina, potrei istruirla a recuperare le previsioni di Borgo a Buggiano e il gioco sarebbe fatto, senza che debbano già essere presenti sulla pagina servita dal server web.
È quello che già succede con i commenti sulle pagine dei post. Sono aggiornati solo quando la pagina viene attivata sul browser. E lo stesso è per i risultati della ricerca sul sito: vengono elaborati e trascritti sulla pagina dopo che la pagina è stata servita al browser; non è il server a comporli, bensì il browser stesso. E lo fa andando a leggersi tutti i testi dei post che sono sul sito.
Cooome, pregooo????
Sì, hai capito bene. Il lavoro lo fa il tuo Browser, e per poterlo fare deve acquisire tutto il testo di tutti i miei post e scansionarlo alla ricerca delle parole che hai richiesto. E lo fa scaricando un file (che tutti i siti più o meno hanno) del feed RSS, che contiene tutti i testi di tutti i miei post, quello che trovi in fondo alla pagina.
Ma quanto mi costa, oh!
Pochissimo, per la verità. Con i pochi post che ci sono adesso sul sito (23 + 4 podcast al momento della stesura), tutto il testo pesa poco meno di 200 KiB, ma trasferito in formato compresso “occupa” circa 60 KiB. Considera che la pagina di ricerca di Google (quella vuota, solo con la casella di ricerca), cerca di scaricare ogni volta più di 3 MiB, mentre per la pagina con i risultati scarica qualcosa come 11-12 MiB di dati. Quindi diciamo che non sono io a dovermi preoccupare troppo…
Ma questo volume aumenterà, e quando sarà sopra quella che considero la mia soglia psicologica (250 KiB), inserirò dei filtri sulla pagina per indicare il periodo che si desidera ricercare, in modo da far svolgere al browser un lavoro tutto sommato minimale.
Per il processo di scansione del testo, invece, il tempo che impiega il browser è davvero irrisorio. Ho inserito una barra di avanzamento, ma anche rallentando il mio browser di 6 volte (c’è una funzione anche per questo!) non riesco a vederla mai riempirsi e la trovo istantaneamente al 100%. Anche in questo caso nel tempo aumenterà, ma non sento al momento l’esigenza di “velocizzarla”. Magari a quel punto mi inventerò qualcosa creando degli indici il più possibile efficienti.
Quando ero pronto con la funzione di ricerca ho avuto però un dubbio. Era o no il caso di inserirla sulla testata di ogni pagina? In un primo momento ho deciso di fare una pagina dedicata alla ricerca. Però poi ho pian piano cambiato idea… In effetti ha senso. Sì, forse si sarebbe più “invitati” a utilizzare la funzione e si potrebbero scoprire nuovi articoli nteressanti senza scorrerli tutti. E dunque ho fatto qualche piccola modifica: sulla barra di navigazione, dove c’era il link alla pagina di ricerca ho inserito una casella di testo editabile e, alla pressione di “Invio”, un piccolo script chiama la pagina di ricerca aggiungendo il testo cercato nell’indirizzo, come parametro. La pagina di ricerca controlla se c’è un parametro e nel caso lo utilizza come termine di ricerca.
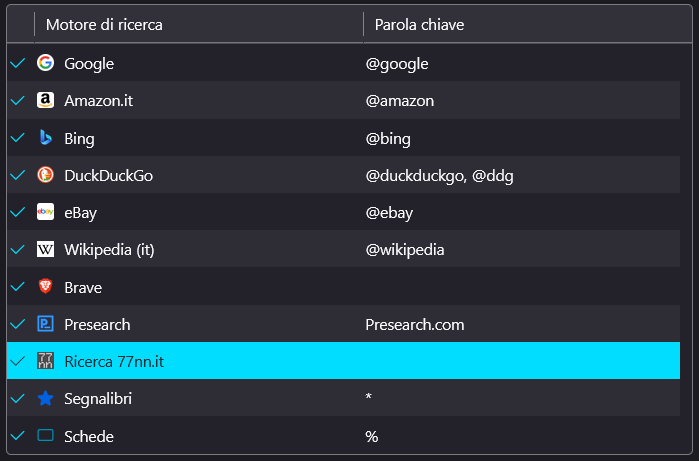
In questo modo, virtualmente, potrei anche preparare un descrittore openSearch e aggiungere la ricerca sul mio sito tra i motori di ricerca del browser… ma perche dovrei???
Come sempre… il codice che ho utilizzato è piuttosto semplice, ma soprattutto accessibile. Non sto pubblicando nulla su Codeberg al momento, perché il mio codice fa schifo… mancano commenti, insomma, è qualcosa di molto artigianale, ma se lo vuoi leggere basta premere F12 e ispezionarlo con i Dev Tools.
Ovviamente, se tu avessi qualche suggerimento per migliorare alcuni aspetti, fammi sapere nei commenti quali altre funzionalità potrei inserire… tra quelle che non richiedono un server pronto ad eseguirle!
Grazie per l’attenzione e al prossimo post!